At sorintlab, in the old days and with customers with “old school” infrastructures we had different ways to make an high available PostgreSQL. We used heartbeat, heartbeat+crm, rhcs, coreosync+pacemaker with a shared storage and a correctly (!!!) configured fencing/stonith.
When moving our infrastructures and customers to cloud based infrastructures (being it a private or a public one), the way to design the infrastructures drastically (and fortunately) changed. Finally our customers were forced to think about the various parts of the infrastructure like something that can break in every moment and that’s also ephemeral. This has always been the case on every infrastructure, but previously the customers tried to ignore this fact and prefered to pay tons of money for something claimed to be “unbreakable”.
In the cloud the “stateful” layers like databases are the most difficult the get right. You can completely offload it to your cloud provider DBaaS offer (like Amazon RDS) or you can implement it by yourself inside the IaaS.
We are more and more focusing on noSQL databases that already provide, given their nature, a shared nothing, sharded and replicated architecture.
But sometimes a relational database is still the best choice or is needed by some products (for example some Hadoop components need a PostgreSQL instance).
Creating an high available PostgreSQL cluster inside an IaaS using the “old school” style is difficult and probably a wrong pattern. First you need a shared storage, this isn’t provided by a cloud provider (for example an aws EBS can be attached to a single machine at a time, and also if you automate, using the aws api, the detach/attach to another machine, an EBS is tied to one availability zone). You can overcome this creating a ceph cluster and attaching a shared rbd to you instances. Then you need a fencing/stonith method to avoid data corruption, you can rely on the cloud api to force stop an instance, but if something goes wrong you need to manually intervene to ensure that the failed instance is really down and force the failover. Additionally you cannot rely on multicast so you should configure your heatbeat/corosync layer to use unicast. Additionally, if you follow the immutable infrastructure approach, you’ll probably have to deal with the changing instances IPs in you heartbeat/corosync layer everytime an instance is terminated and recreated. Then we have to find some solutions also to achieve a VIP for the instance (for example a script to move an elasticIP to another instance). All of this looks like a workaround and not the right approach.
So another way to achive PostgreSQL high availability is needed. Following the shared nothing approach of other noSQLs we can leverage the great postgres’s streaming replication to achieve this. You can easily create a master and some replicas with asynchronous or synchronous replication. The next step is to automate the failover when the master instance is unhealthy. There are various good tools to achieve this (for example repmgr or governor).
After experimenting with them we noticed that they were difficult to implement in an IaaS or inside a container orchestrated environment (like kubernetes, nomad etc…) (changing IPs, different advertised IPs etc…). Additionally, since one of the main goal was to achieve the most possible data consistency, these tools didn’t provide the needed resilency to the possible types of network partitioning. For example it’s difficult for a client to point to the right master during a network partition, it can happen that a new master is elected also if the old one is active (but partitioned) and some of the clients’ sessions continue to communicate (and also do writes) to the old one causing data loss/inconsistencies. There’s the need to find a way for the client to connect to the right master and also forcibly close connections to the old one.
At the end our primary goals were:
- Cloud native PostgreSQL High Availability.
- Resilency to all the possible network partitioning problems.
- Easy cluster setup in minutes (from scratch or from an existing instance)
- Easy cluster administration and configuration
- Easy cluster scaling
To achieve all of these goals we created stolon, a cloud native high availability manager for PostgreSQL.
Stolon is made up of 3 main components:
- keeper: it manages a PostgreSQL instance converging to the clusterview provided by the sentinel(s).
- sentinel: it discovers and monitors keepers and calculates the optimal clusterview.
- proxy: the client’s access point. It enforce connections to the right PostgreSQL master and forcibly closes connections to unelected masters.
- stolonctl: A cli to view the cluster status and manage the cluster.
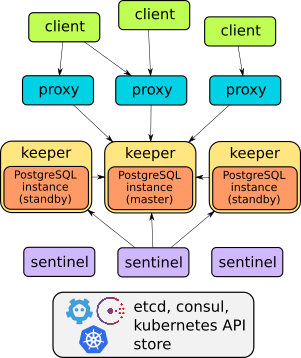
With these three components and using some of the best high available data stores like etcd and consul (and in future also zookeeper) for saving the cluster view and doing sentinels leader election we achieved our goals.
Please take a look at the various docs and examples (more to come) available on the stolon github project.
Stolon is an open source project under the Apache 2.0 license, it’s in continuous improvent and contributions are gladly welcomed!