Note: A simplified but complete way to see and test all of this in action is available on github.
Since we are always promoting new methodologies and technologies to our customers, the last years were full of projects based on IaaS (public and private) managed using Infrastructure as Code. Today, with the experience we gained in these years using different solution and technologies, I’d like to describe one way to manage an immutable infrastructure.
To make the below description the simplest I’m going to skip all the various parts related to application containers and their orchestration (that we are deeply using) (since also this is immutable infrastructure) and their way to do upgrade of stateless services (rolling vs blue/green deployments) but I’m going to just focus on the IaaS immutable infrastructure and in particular on how to handle rolling upgrades of stateful services.
I’m not going to explain here (it deserves a dedicated post) all the rationales that brought us to this solution and why some technologies over other (and this will probably change in future).
First a brief list of the primary requirements that this solution tries to satisfy:
- We want to be able to create from scratch in minutes complete test environments as much as possible similar to the production environment. In this way we can run reliable integrations tests for every pull request (but also making the developers run the tests by themself).
- We want to avoid the management problems and the uncertain of the upgrade consistency of our infrastructures using classic provisioning.
- We want to create our server images and test the new infrastructure creation and upgrade before doing this in production.
- We have to manage high available stateful services (databases etc…) that needs to be upgraded without downtime.
- Manage independent block of the full infrastructure and handle the dependencies between them.
To achieve this primary requirements we ended up creating an IaaS Immutable infrastructure using packer for image creation and terraform for infrastructure creation/upgrade all integrated to achieve rolling upgrades of stateful services. Everything fully testable.
Being an infrastructure as code every component has its own repository and (treating it just like an application), we use a typical build/test/deploy cycle integrated in a CI/CD workflow.
For example, suppose we want to create a consul cluster, we are going to use two repositories:
- The image repository: it contains the packer template and all the files needed to create the final image.
- The infrastructure repository: it contains the terraform configuration and various script to obtain the two primary functions: create and upgrade (and their related tests).
Image repository
The build artifact of this repository is an image (aws AMI, openstack image etc…). Every pull request/commit triggers a CI build that creates an image and verifies its correctness (at the end the image is removed). When we have a working image we can tag its commit and the CI build will do the same without removing it (and tagging it to make it easily discoverable).
Infrastructure repository
The build artifact of this repository is a docker image containing all the scripts and tools needed for managing the immutable Infrastructure. We created a container to make also the required toolset “immutable”. This docker image can be executed with different commands. The primary ones are create, upgrade, test-create, test-upgrade.
- create is used to create an Infrastructure from scratch.
- upgrade is used to do the rolling upgrade of an existing infrastructure.
- test-create is used during the tests. It’ll create a temporary infrastructure and destroy it at the end of the tests.
- test-upgrade is used during the tests. It’ll create a temporary infrastructure at the previous version (executing the docker image at the previous version with the create command), perform the upgrade and then destroy it at the end of the tests.
Every pull request/commit triggers a CI that will build and execute the created docker image with test-create and test-upgrade. When everything is ok we can tag a commit and in this case we can use the built image to execute the real upgrade (“create” will be used only for the first time) on our production environment.
Why two different commands (create and upgrade)?
The create function is used to create a new environment at a specific version (usually the latest). We use it for creating all the test environments for the various application and also for testing the infrastructure rolling upgrade. Instead our production infrastructure (except for the first version that will be created) needs to be upgraded. We cannot destroy the production infrastructure and recreate a new one but we want to do a zero downtime upgrade.
For stateful services this rolling upgrade doesn’t destroy the attached ebs volumes (containing the stateful data) but detaches and reattaches it to the new instances. In this way we avoid possible long full resync times needed at every instance recreation step.
Why terraform?
Terraform is really powerful because we can declaratively define our infrastructure and it’ll calculate and execute the plan to reach the required state.
We use the same declaration for create and upgrade, so we don’t have to write different configurations for infrastructure creation and for every upgrade to a newer version (like usually needed when using something like ansible ec2 modules).
In the create function what we have to do is just simply run a terraform apply. Instead in the upgrade function we cannot just run a terraform apply because terraform will calculate the plan to achieve the new status but will execute it as fast as possible. We can also try to limit its parallelism but, what we want to do, is to test, between every instance recreation, that everything is correctly working before moving the the next instance.
There are various issues (see this) opened in the terraform github project requesting support for rolling upgrades, but given it’s declarative syntax I’m not sure it will easily fit in it. For example, between every instance recreation we are going to do various tests (we wait for the instance coming up, connect to it and verify that the ebs volume is mounted and than verify that consul correctly reentered in the cluster and that the cluster is fully quorate), so a lot of steps that are difficult to define in the terraform declarative syntax.
But this isn’t a problem, we can just create a script that will apply the terraform changes in little steps targeting only some resources, and do all what’s needed between these steps (pre/post operations). As an example of a pre operation (see this issue) we have to stop the instance before detaching an ebs volumes or the detach will fail since the volumes is mounted inside the instance.
Multiple infrastructure blocks
Additionally the terraform state files (which are saved in a remote repository, for example on S3 or swift) can be used by other blocks of the full infrastructure to gather all the required fact (for example the vpc id, subnets etc…)
Indeed, the full infrastructure may grow adding more applications/microservices. And some of these can require some dedicated instances (for example for the stateful services, since actually, for various reasons, we prefer to run them outside a container orchestrator). Usually these instances are isolated and related to their microservice but can also depend on a base infrastructure (like a consul cluster).
Every block of the infrastructure is managed separately from the other parts but may depends on them (and on specific versions). So there’s the need to keep a dependency management between these blocks.
For example, in our latest project, we created an immutable infrastructure based on consul, nomad, stolon and we are going to test our microservices, creating from scratch, for every test run, a new consul cluster (the above base infrastructure), a nomad cluster, the databases required for the microservice (restoring and obfuscating sensitive data from the latest database backup), plus all the other microservices needed for this application. This takes just few minutes. Internally all the blocks of the infrastructure (instances, microservices etc…) define their dependencies and these are resolved to create the minimal test environments required to test them.
This image represents the infrastructure instances:
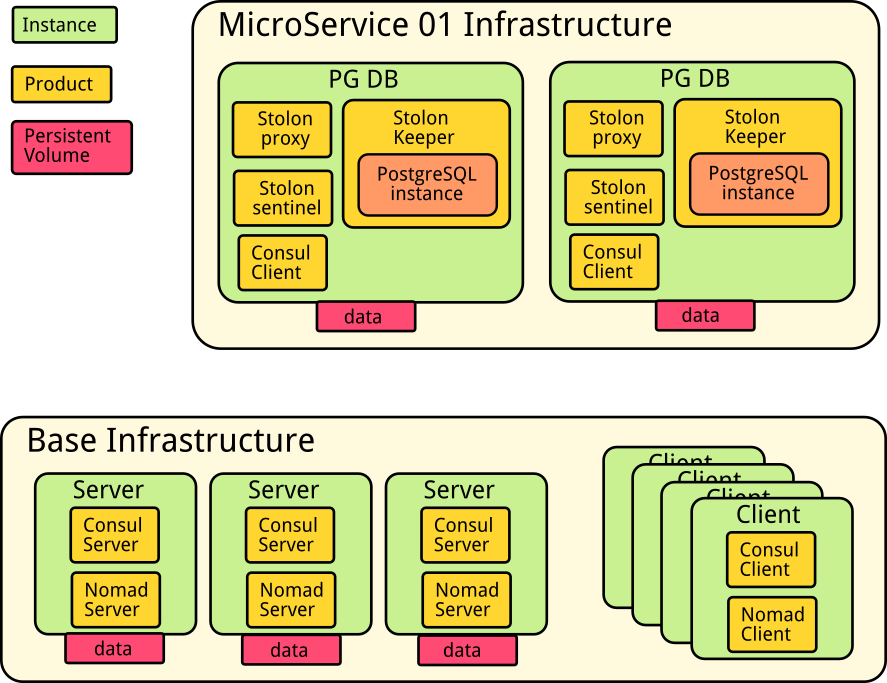
As you can see there are two blocks. A base infrastructure and a microservice01 infrastructure. This microservice has its own database, while the stateless part (the application) will run inside the nomad cluster. There’s also a microservice02 but, since its only stateless it doesn’t need any dedicated instance.
And these are the project dependencies:
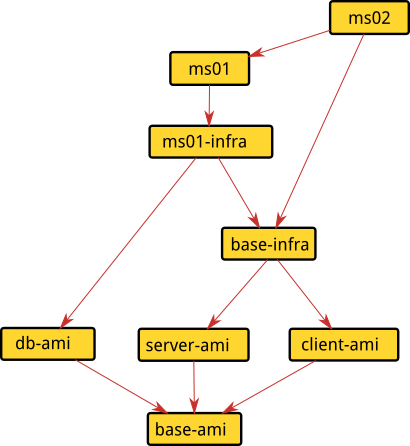
Example repo
The example repo will let you try all of this in a simplified but quite complete way. It uses Amazon aws to create a consul 3 nodes cluster and do a rolling upgrade to a newer version. Being just one repo both the image repository and the infrastructure repository are available under different directories and the different versions are subdirectories. Please take a look at its README.md to see all the prerequisites and the example steps.